1. 컴퓨터 구조

16 비트 중에 7비트는 Opcode이고, 이 Opcode에 따라 뒤의 9비트가 어떤 포맷인지 정해진다. 그림을 보면 Register, Immediate, Jump and Branch에 대해 나타내고 있으며 아래의 예시를 통해 각각 어떤 동작을 위한 Instruction format인지 알 수 있다.
Register 방식 : R0 ← R1 + R2
Immediate 방식 : R0 ← R1 + 3
Jump and Branch 방식 : R0에 저장되어 있는 주소로 가서 값을 가져올 때 (PC값 변화)
- PC 상대주소지정방식: PC를 기준으로 주소 offset을 2의 보수 형태로 저장
8개의 레지스터가 있을 때, 각 오퍼랜드는 3bit를 사용한다.

한 클럭 사이클에 한 개의 명령어를 실행할 수 있다. 위의 그림을 보면 최소 3 사이클이 필요한 것을 알 수 있다.
1. PC에서 명령어를 인출하여 메모리에 저장한다.
2. Instruction decoder - 명령어해독, 연산 종류, 오퍼랜드 결정, 제어 신호 발생시킨다.
3. 오퍼랜드로부터 ALU 연산하여 data 메모리에 R/W
PC는 현재 명령어 인출 후 +1이 자동으로 증가되며, Branch/Jump 시는 증가 이전 값에 offset 처리된다.

예시의 그림은 Memory가 asynch였기 때문에 위와 같은 구조에서도 3사이클이 가능했다. 하지만 현재는 sync memory를 사용하기 때문에 MUXS의 연결을 끊고 PC와 바로 연결해주어 3 사이클로 만들었다.

위의 표를 보면,
1. IF 상태일 때, IR ← M[PC] PC 지정주소에서 instr read
PC ← PC+1 다음 instr을 위해 자동증가
2. EX0 상태일 때, IR값에 따라 instruction decoding -> opcode값에 따라 필요한 마이크로 연산 실행로 분기 (MUXC에서 MC =1)
3. opcode에 맞는 명령 수행 후 IF로 돌아감
2. CPU - ALU unit설계
2-1 Arithmetic Circuit
ALU unit의 Arithmetic Circuit을 먼저 만든다.
module fa1 (a, b, ci, co, g);
input a, b, ci;
output co, g;
assign co = ( a & b) | (ci & a ) | (ci & b);
assign g = a ^ b ^ ci;
endmodule
module func_Arith (A, B, S, Cin, G, tcout);
parameter BW = 16;
input [BW-1:0] A, B;
input Cin;
input [1:0] S;
output [BW-1:0] G;
output [1:0] tcout;
reg [BW-1:0] Y;
wire [BW:0] Cout;
assign Cout [0] = Cin;
assign tcout = Cout [16 : 15];
always @ (*)
begin
case(S)
2'b00 : begin Y= 16'b0; end
2'b01 : begin Y= B; end
2'b10 : begin Y= ~B; end
default : begin Y= 16'b1111111111111111; end
endcase
end
genvar i;
generate
for (i=0; i<BW; i=i+1) begin : add
fa1 FA_16b (.a(A[i]), .b(Y[i]), .ci(Cout[i]), .g(G[i]), .co(Cout[i+1]));
end
endgenerate
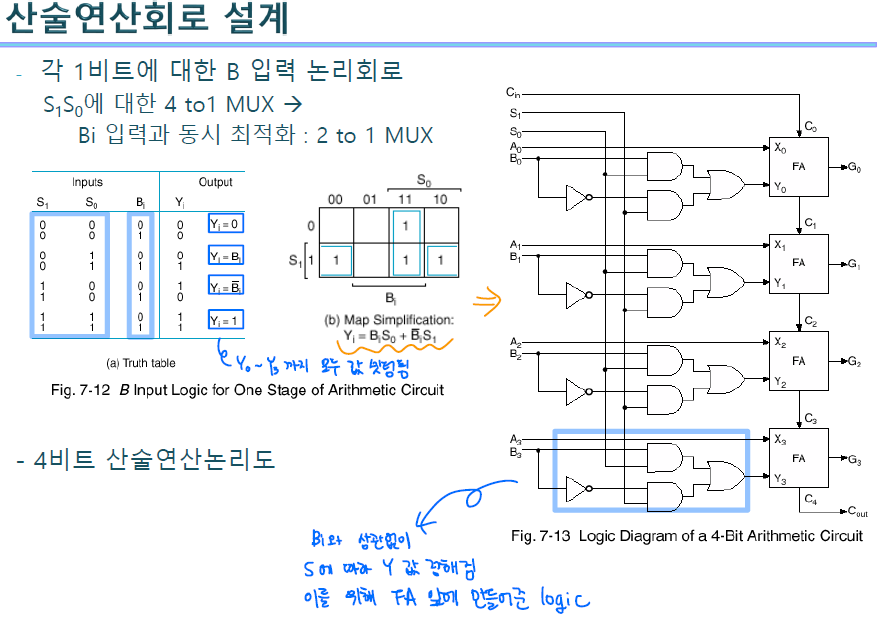
endmodule1bit짜리 에더를 instanciation하여 16비트 짜리로 만들었다. 그리고 Y0 앞의 logic을 표현해줘야 했는데, 구조적 모델링 방식으로 gate를 만들어 연결하는 식으로 구현할 수도 있지만, 최대한 구조적 모델링을 지양하고 동작적 모델링으로 작성하였다. truth table을 보면 B의 값과 상관없이 Select신호에 따라 Y가 결정되기 때문에 wire Y를 선언하여 case문을 사용하여 작성해주었다. 이 때 16비트로 동일하게 만들었다. 이 때 유의할 점은 assign문에서 쓰일 땐 wire로, always ~case문에서 쓸 땐 reg로 선언해주어야 한다는 점이다. tcout은 c_flag와 v_flag (carry out, overflow) 생성을 위해 두 비트 할당하여 포트로 뽑아주었다.
2-2 Logical Circuit

module func_Logical (A, B, S, G);
parameter BW = 16;
input [BW-1:0] A, B;
input [1:0] S;
output reg [BW-1:0] G;
always @ (A,B,S,G)
begin
case(S)
2'b00 : begin G = A & B; end
2'b01 : begin G = A | B; end
2'b10 : begin G = A ^ B; end
default : begin G = ~A; end
endcase
end
endmodulelogical은 위와 같이 간단하게 작성해주었다.
3. ALU unit
module ALU (oprA, oprB, Cin, sel, gout, v_flag, c_flag, n_flag, z_flag);
parameter BW = 16;
input [BW-1:0] oprA, oprB;
input Cin;
input [2:0] sel;
output [BW-1:0] gout;
//output [1:0] Cout;
wire [1:0] Cout;
output v_flag, c_flag, n_flag, z_flag;
wire [BW-1:0] dout_L, dout_A;
assign gout = (sel[2] ? dout_L : dout_A);
func_Logical Logical_circuit (.A(oprA), .B(oprB), .S(sel[1:0]), .G(dout_L));
func_Arith Arith_circuit (.A(oprA), .B(oprB), .S(sel[1:0]), .Cin(Cin), .G(dout_A), .tcout(Cout));
//NZVC
assign v_flag = Cout[1] ^ Cout[0];
assign c_flag = Cout[1] ;
assign n_flag = gout[BW-1];
assign z_flag = ~(|gout);
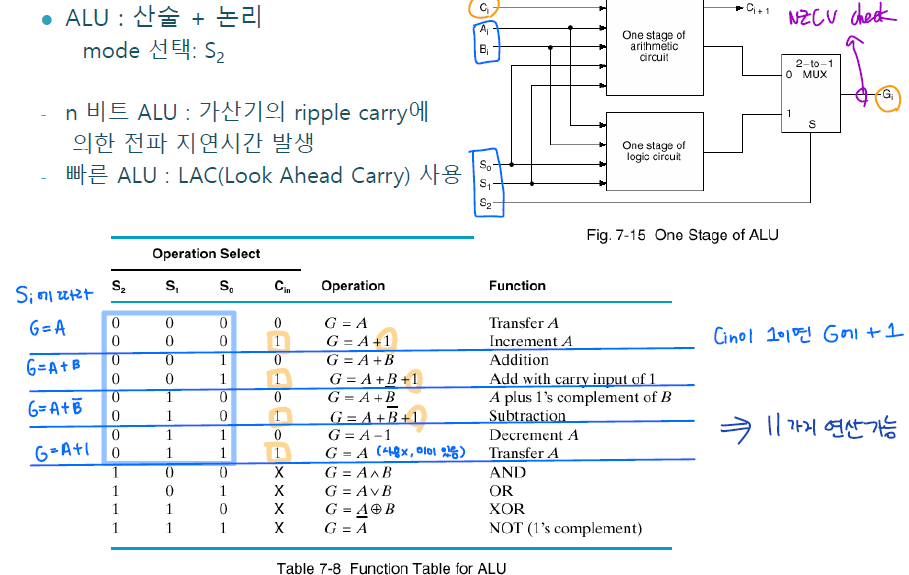
endmodule위에서 작성한 두 모듈을 인스턴시에이션하여 ALU unit을 완성하였다. arith와 logical 은 완성이 되어 있고, 그림과 표를 보면 결국 S[2]에 따라 arith 혹은 logical 의 결과가 ALU의 output으로 결정되는 것이기 때문에 assign으로 나타내주었다. arith에서 뽑아낸 Carry out 두 비트를 이용하여 v_flag와 c_flag를 만들었고, ALU output negative flag와 zero detect flag도 작성해주었다.
- v_flag : arith의 마지막 에더의 carry in과 carry out 비교
- c_flag : carry out값 (0 or 1)
- n_flag : ALU 연산 결과값의 MSB (부호) negative인지 비교
- z_flag : ALU 연산 결과값 모든 비트(16비트) NOR하여 0이 있는지 detect (0이 있으면 1)
다음은 ALU의 회로와 시뮬레이션 결과이다.

<ALU 테스트벤치>
`timescale 1ns /1ps
module tb_ALU;
reg [15:0] oprA, oprB;
reg Cin;
reg [2:0] sel;
wire [15:0] gout;
wire v_flag, c_flag, n_flag, z_flag;
ALU u1 (oprA, oprB, Cin, sel, gout, v_flag, c_flag, n_flag, z_flag);
initial
begin
sel = 3'b000; Cin = 1'b0; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b000; Cin = 1'b1; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b001; Cin = 1'b0; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b001; Cin = 1'b1; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b010; Cin = 1'b0; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b010; Cin = 1'b1; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b011; Cin = 1'b0; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b011; Cin = 1'b1; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b100; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b101; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b110; oprA = 16'h4; oprB = 16'h8;
#10 sel = 3'b111; oprA = 16'h4; oprB = 16'h8;
#10;
$stop;
end
endmodule

정상적으로 수행됨을 알 수 있다.
'[Harman교육] 베릴로그' 카테고리의 다른 글
| [23.03.23] CPU 설계 - datapath (1) | 2023.03.23 |
|---|---|
| [23.03.22] CPU설계 - Shifter unit (0) | 2023.03.22 |
| [23.03.20] CPU 설계 기초 (0) | 2023.03.20 |
| [23.03.17] 무어/ 밀리 모델 (0) | 2023.03.17 |
| [23.03.14] 조합회로와 순차회로 -2 (0) | 2023.03.16 |